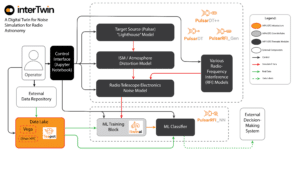
For the first time since the field of radio astronomy was created in the middle of the 20th century we can no longer deal with the data in the traditional way. With the old radio telescopes the volume of data collected was relatively small, so the principle “the original data is sacred” was typically invoked: all the raw data were kept indefinitely or until the scientists in charge of the project decide that it is OK to delete it, which was normally years after the completion of observations. But with the new generation of telescopes like the South African MeerKAT or the Australian ASKAP, precursors to the Square Kilometre Array (SKA) telescope we no longer have such luxury: they collect so much raw data that it is simply physically impossible to keep it for more than a few weeks, even the best data storage facilities would quickly reach their limits. Of course with such volumes it is also impossible to use experts to manually sort through the data and decide what should be kept and what can be safely deleted: this task must fall to machine learning-based automated decision-making systems.
This unfortunately raises another problem: because of the sheer volumes of data involved such systems must be HPC (high performance computing)-capable, that is to be run on modern supercomputers. Otherwise the system would not be able to keep up with the telescope in real time and the data flooding would still occur. But most modern radio-astronomical data processing tools were written with small computers in mind and so handle parallelization (the main computing principle of the HPC) poorly.
On the other hand, once an automated decision-making system is ready, it can do more than just resolve the data overflow problem. We can finally approach the most mysterious subject of radio astronomy: radio transients. Radio transients are sources that drastically change their brightness over time. In the worst cases they are just short “blips” of radio emission in random directions, one cannot predict where or when they happen and so can observe them only by an extremely lucky coincidence. Tantalizingly, it is believed that these phenomena may be produced by exotic events at extreme distances, for example by a collision of two black holes, and so they can provide us with clues about some very interesting and powerful astrophysical processes that cannot be gleaned in any other way. And an automated expert system running on a modern radio telescope surveying a large area of the sky can be taught to discern a transient and point the telescope at it. It can also trigger the “target of opportunity” mode at other observatories, making powerful infrared, optical or X-ray telescopes to point at the transient and possibly learn much more about the event: what is brief and weak in radio frequencies may be long and bright at other wavelengths.