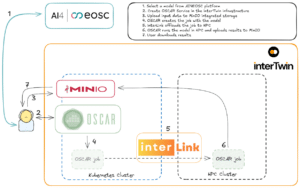
Integrating cloud-native AI inference workflows with large-scale HPC infrastructures poses a number of nontrivial challenges, both technical and architectural.
One fundamental challenge was enabling transparent and secure offloading of containerised workloads from elastic, cloud-based Kubernetes environments to HPC systems like VEGA, which operate under different execution and scheduling paradigms.
Equally critical was the need for automated, end-to-end service execution that abstracts infrastructure complexity from users, preserving usability without compromising performance or flexibility.
The collaboration between interTwin and AI4EOSC confronted these head-on to demonstrate how Digital Twin applications can execute AI-driven scientific workflows across the Computing Continuum.